VTD-XML Benchmark Report for Version 2.3
(Part III)
Objective
Since its initial release, VTD-XML has undergone several rounds of improvement. This report show how well VTD-XML fares against some of the well-known XML parsers. The old version of the benchmark can be found here.
Testing Methodology
Hardware
- Processor: Core2 Duo T9300 2.5GHz (6MB L2 integrated cache).
- Memory: 3GB 800Mhz FSB
Software
- Windows Vista Business
- JDK version 1.60; default set to server JVM.
- XML parsers: Xerces DOM (with and without node expansion) and SAX version 2.7.1, VTD-XML 2.3 in Java (with and without buffer reuse), XPP3 1.1.3.4.O, Piccolo 1.04, and VTD-XML 2.3 in C
Benchmark Apps
For DOM and VTD-XML, the benchmark programs generate hierarchical structures.
For SAX and PULL parsers, the benchmark programs scan over the entire documents without any processing logic.
Notes on Performance Tuning and Performance Measurement
For performance numbers, all benchmark programs first loop thru the parsing code a number of iterations so the server JVM compile them into native code to obtain optimal performance, before the real measurement of parsing throughput and latency starts.
It should be noted that comparing VTD-XML with SAX or PULL is not really fair comparisons: VTD-XML allows random access; SAX and Pull are forward only.
A wide selection of XML files, ranging from very small (1k) to big (15MB) are chosen and grouped into small (<30k), medium sized (<3M), and big.
Benchmark programs for measuring parsing performance can be downloaded below:
- benchmark.java (VTD-XML)
- benchmark_BR.java (VTD-XML with buffer reuse)
- benchmarkSAX.java ( JDK's built-in SAX parser)
- benchmarkDOM.java (JDK's built-in DOM parser)
- benchmarkDOM_d.java ( Deferred node expansion)
- benchmarkPiccolo.java ( Piccolo SAX parser, widely considered to be the performance leader)
- benchmarkPull.java (XPP3)
Benchmark programs for measuring memory usage can be downloaded below
- benchmark_mem.java (VTD-XML)
- benchmarkDOM_mem.java (JDK's built-in DOM parser)
- benchmarkDOM_mem_d.java (deferred node expansion)
Benchmark programs for doing node iteration can be downloaded below
- benchmarkDOM_nav1.java (use DOM's node iterator)
- benchmark_nav1.java (use VTD-XML's autoPilot's iterator)
XML files used in the benchmark can be downloaded here.
Parsing Performance
Throughput Comparison
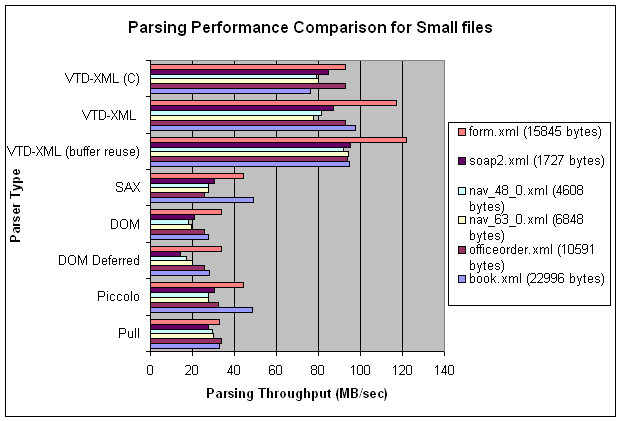
- Small files
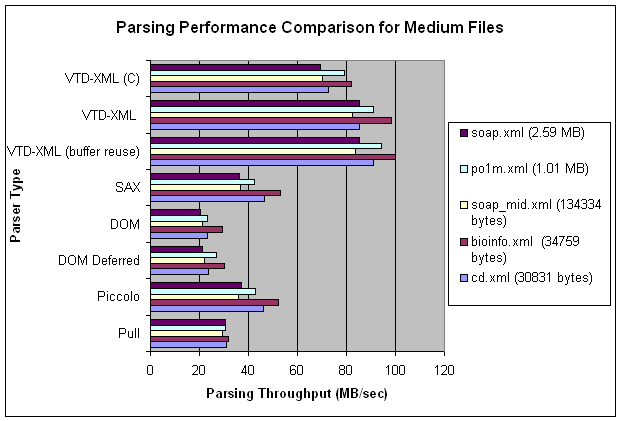
- Medium Sized files
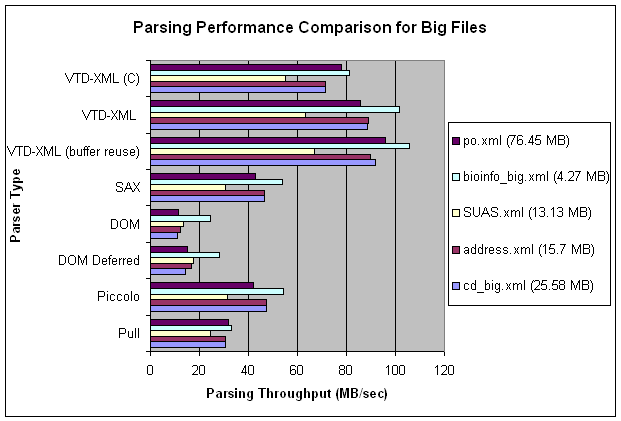
- Big XML files
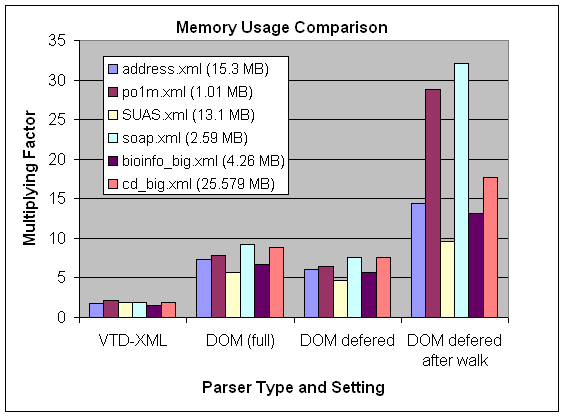
Memory Usage
Because SAX and Pull do not build data structures in memory, so the meaningful comparison is between DOM and VTD-XML. To that end, we benchmark the multiplying factor which is the ratio between the memory usage and the document size.
Navigation Performance
The goal for this part is to benchmark the performance of the XML parsers visiting every single node after finishing building the hierarchical structure.
Small Files
| File name/size | VTD-XML (ms) | DOM(ms) |
| soap2.xml (1727 bytes) | 0.003325 | 0.002645 |
| nav_48_0.xml (4608 bytes) | 0.009075 | 0.009475 |
| nav_63_0.xml (6848 bytes) | 0.015375 | 0.01631 |
| officeOrder.xml (10591 bytes) | 0.0252 | 0.0206 |
| book.xml (22996 bytes) | 0.0763 | 0.0705 |
Mid-Sized Files
| File name/size | VTD-XML (ms) | DOM(ms) |
| bioinfo.xml (69457 bytes) | 0.297 | 0.28 |
| cd.xml (92348 bytes) | 0.1128 | 0.11816 |
| soap_small.xml (126734 bytes) | 0.1176 | 0.074 |
| po1m.xml (1.01 MB) | 4.055 | 4.9 |
| soap.xml (2.59 MB) | 11.44 | 13.4 |
Large Files
| File name/size | VTD-XML (ms) | DOM(ms) |
| bioinfo_big.xml (4.27 MB) | 12.5 | 17.43 |
| SUAS.xml (13.13 MB) | 13.46 | 7.12 |
| address.xml (15.24 MB) | 44.52 | 59.62 |
| cd_big.xml(25.8 MB) | 102.38 | 164.31 |